Guide to Context Engineering: How to Optimize Tokens and Avoid Context Bloat in AI Agents
LLM cost

The evolution of development with Large Language Models (LLMs) has moved far beyond basic prompt engineering. Today, the true engineering bottleneck in building autonomous agents lies in Context Engineering: the art and science of curating and optimizing the payload of tokens that populate a model’s context window during its execution lifecycle.
When an agent operates within an iterative loop (planning, tool invocation, observation, and re-planning), the volume of accumulated data grows exponentially. Left unmanaged, this accumulation inevitably triggers Context Bloat and its direct consequence, Context Rot (attention degradation).
1. Token Economics and Transformer Physics
To understand why optimization is critical, we must look at the underlying architecture. Transformer-based models rely on a self-attention mechanism whose computational cost (and often latency) scales quadratically, expressed as O(n^2) relative to the number of tokens n.
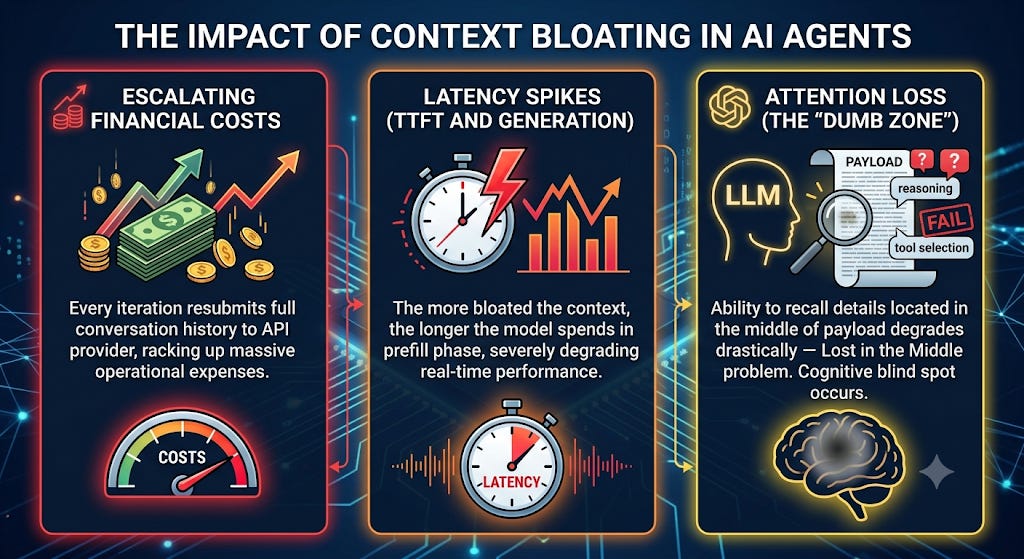
A context saturated with redundant tokens introduces three critical failure modes:
Escalating Financial Costs: Every iteration of the agent resubmits the entire conversation history to the API provider, racking up massive operational expenses.
Latency Spikes (TTFT and Generation): The more bloated the context, the longer the model spends in the prefill phase, severely degrading real-time performance.
Attention Loss (The “Dumb Zone”): As token volume grows, an LLM’s ability to recall specific details located in the middle of the payload degrades drastically—a phenomenon known as the Lost in the Middle problem. The agent enters a cognitive blind spot where reasoning and tool selection begin to fail.
2. The Two Faces of Context Bloat in Agents
In agentic workflows, context bloat primarily manifests through two vectors:
System & Tool Definition Bloat : To maximize an agent’s capabilities, developers frequently pack the system prompt with dozens of function definitions (tools) and exhaustive behavioral guidelines. Consequently, the agent begins every single turn with a baseline overhead of thousands of wasted tokens before even processing the user’s latest input.
Conversation & Observation Bloat : Within an agentic loop, tool outputs (such as raw SQL query results or terminal logs) are fed back into the context as an “Observation.” If a tool returns a 500-line JSON payload, the context window is instantly polluted with low-signal noise.


3. Architectural Optimization Strategies
Mitigating these issues requires implementing structured software design patterns.
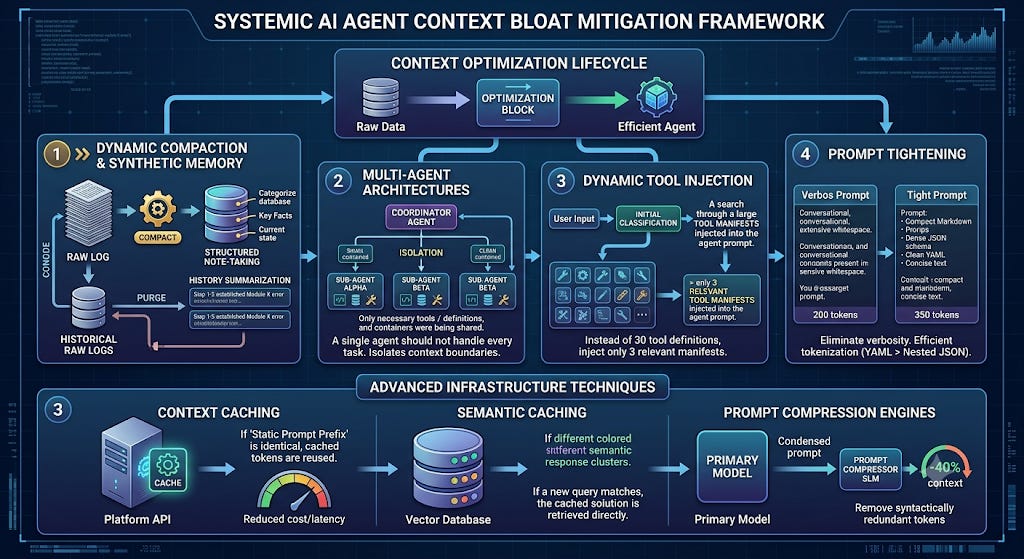
Dynamic Compaction and Synthetic Memory
Instead of maintaining a raw, line-by-line log of every historical step, you must implement a Context Compaction cycle.
Structured Note-taking: The agent actively updates an internal “scratchpad” or state object, synthesizing only key discoveries and the current objective status.
History Summarization: Once a specific token threshold is breached, an asynchronous background process condenses past turns (e.g., “Steps 1 through 5 established that the error originates in module X”), purging raw logs while preserving semantic continuity.
Multi-Agent Architectures and Sub-Agents (Isolation)
A single agent should not handle every task. Dividing responsibilities allows you to isolate context boundaries.
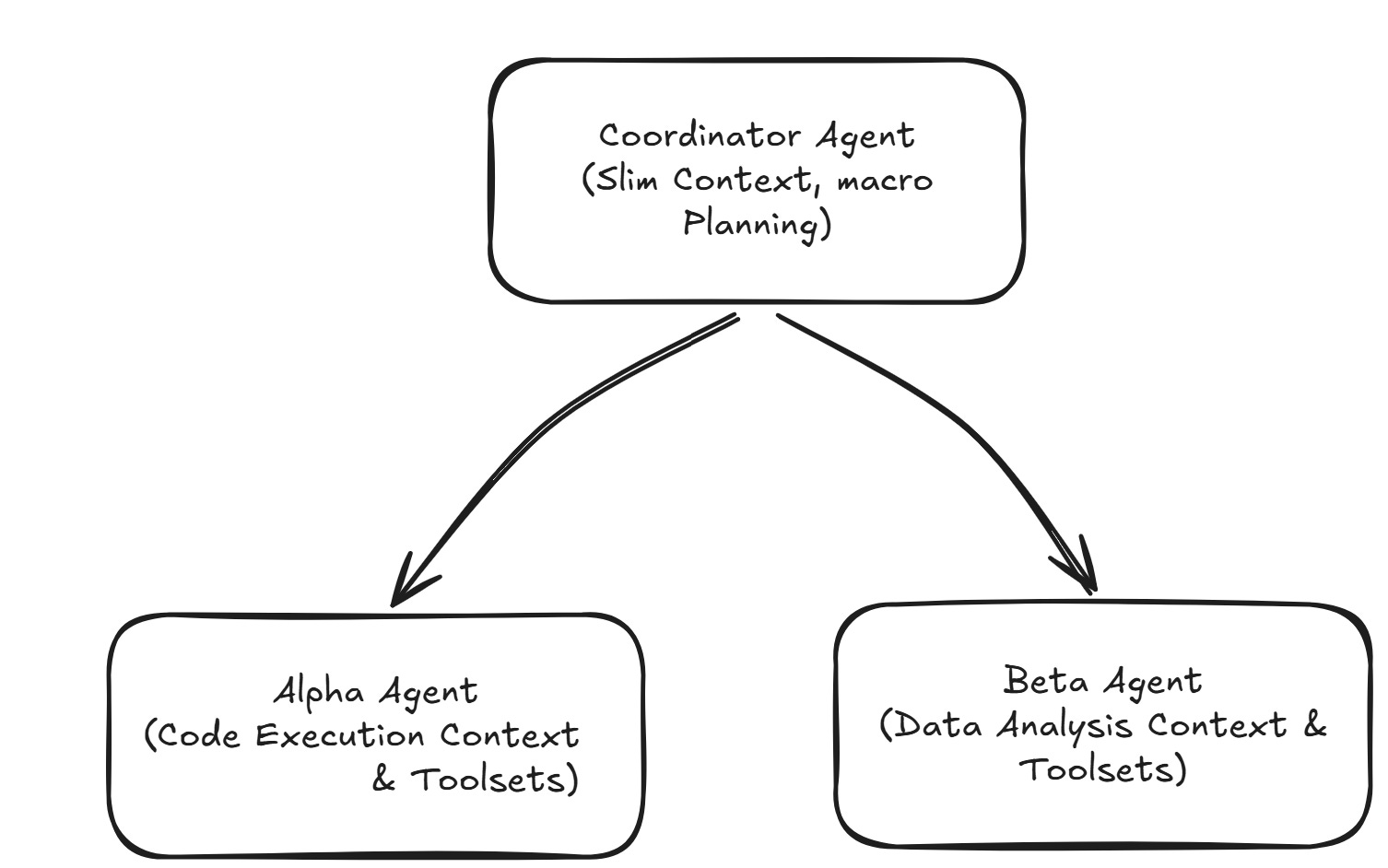
By isolating sub-agents, specialized tools—and their accompanying definition tokens—are only loaded when strictly necessary, keeping the coordinator agent lightweight and focused.
Dynamic Tool Injection
Instead of passing 30 tool definitions to the LLM on every call, use an initial classification step or a vector search approach to inject only the manifests of the 3 tools directly relevant to the current operational step.
Prompt Tightening
Eliminate Verbosity: Replace conversational instructions with structured constraints like compact Markdown or dense JSON Schemas.
Efficient Tokenization: Choose data serialization formats wisely. For example, a clean YAML snippet often consumes significantly fewer tokens than an identical, deeply nested JSON payload formatted with heavy whitespace.
4. Advanced Infrastructure-Level Techniques
Beyond application design, modern LLM infrastructure offers deterministic solutions to slash costs and boost throughput:
Context Caching: Platforms like Anthropic’s API and Google Gemini allow you to cache static tokens (such as extended system prompts and tool definitions). If the prefix of the prompt remains identical across agent turns, the cached tokens are reused, drastically reducing input costs and prefill latency.
Semantic Caching: Utilize vector databases to cache agent responses to similar sub-tasks or queries. If a sub-agent has already solved a matching problem in a previous loop, the solution is retrieved from the cache instantly without triggering another LLM inference call.
Prompt Compression Engines: Tools like LLMLingua leverage Small Language Models (SLMs) to analyze prompts and remove syntactically redundant tokens before they hit the primary model, preserving up to 95% of reasoning performance while compressing the context by up to 40%.
5. Implementations
Major cloud vendors and data platforms have introduced native architecture primitives to handle context bloat, state synchronization, and long-term agent retention systematically.
Snowflake: Cortex AI & Semantic Search Services
Snowflake tackles context bloating by leveraging its cloud data platform directly alongside its Cortex AI suite. Instead of maintaining long state paths in active application memory:
Vector Data Pipelines: Raw operational logs and agent observation outputs are streamed dynamically into Snowflake tables and vector indexes via Cortex Search.
State Store Integration: Multi-agent state orchestration relies on transactional SQL tables acting as an external, structured state channel, ensuring agents pull minimal, highly refined context slices during turn evaluations rather than the full session footprint.
Databricks: Unity Catalog & Mosaic AI Agent Framework
Databricks approaches context management through governance and semantic integration:
Context Tool Tracking via Unity Catalog: Tool and function specifications are treated as data assets governed by Unity Catalog. Rather than packaging all tools inside an agent’s setup prompt, the Mosaic AI Agent Framework uses real-time tool discovery to inject only the relevant tools based on user activity.
Vector Search Syncing: Conversation logs are automatically ingested through Delta Live Tables into Databricks Vector Search, providing structured background summarization on historic runs seamlessly.
Microsoft Azure: Azure AI Foundry & Cosmos DB Memory Store
Microsoft addresses context engineering by integrating its cloud native orchestration layers with hyper-scalable state storage:
Azure AI Search & Cosmos DB: Azure uses Cosmos DB as an transactional session memory engine configured with native vector capabilities. It automates sliding window trims and stores historic turns directly in Cosmos DB.
Semantic Kernel Integration: Native support for semantic chunking and automated prompt compression tools (such as native token pruning within Azure AI Foundry pipelines) optimizes payloads before routing them to Azure OpenAI endpoints.
Amazon Web Services (AWS): Amazon Bedrock Agents & Memory Storage
AWS provides built-in enterprise abstractions directly inside Amazon Bedrock Agents:
Session Memory Persistence: Bedrock Agents natively maintain short-term and long-term memory across chat sessions. The infrastructure layer automatically manages session state retention, abstracting the pruning logic away from application-level Python code.
Dynamic Knowledge Base Retrieval: It natively orchestrates the chunking, embedding, and precision-injection of historical contexts via Amazon OpenSearch Serverless, minimizing unnecessary noise in the prompt window.
6. Open-Source GitHub Projects
If you are looking to implement custom context optimization layers within your own engineering stack, these three open-source repositories provide foundational tooling:
Microsoft AutoGen (microsoft/autogen)
A robust framework for developing multi-agent applications using multiple cooperating agents.
Why it matters for context engineering: AutoGen natively implements the Isolation pattern. By splitting broad objectives among specialized, isolated agents (e.g., separating a coder from a code-reviewer), it prevents a single agent from accumulating tool definitions and massive observation bloats, fundamentally restricting individual token usage.
Microsoft GraphRAG (microsoft/graphrag)
A structured, data-first RAG approach that builds a knowledge graph from raw text inputs.
Why it matters for context engineering: Traditional vector search can overflow context windows with unstructured chunks when queried about complex, overarching topics. GraphRAG structures historical data into hierarchical graph communities, allowing agents to query high-level, semantic global summaries. This significantly lowers token overhead compared to injecting massive blocks of uncompressed raw text.
🧑💻Let’s coding
Also check our project about iiot-graph RAG:
git clone https://github.com/venergiac/iiot-graph-ragMemGPT (corgi-ai/memgpt / Letta)
An open-source project designed to give LLMs managed operating-system-like memory (inspired by traditional OS virtual memory architectures).
Why it matters for context engineering: MemGPT completely decouples the agent’s actual long-term memory from the LLM’s fixed context window. It introduces an architecture where the active context functions like RAM (Main Memory) and a vector database/document store acts as a Hard Drive (Disk). The agent writes explicit commands to “page” information in and out of its primary context, allowing it to maintain infinite-horizon conversations without suffering from context bloat or “Lost in the Middle” attention degradation.
Pruner / Prompt Compression Repositories (e.g., princeton-nlp/SWE-bench utility tools or text-pruner)
A category of open-source token optimization utilities (such as tokenizer-based semantic filters or regex-based JSON-to-YAML minifiers).
Why it matters for context engineering: These lightweight utilities focus on strict code, log, and data serialization cleanup before payloads hit the network. By intercepting raw data within your Python agentic loops, these tools strip heavy JSON whitespaces, truncate massive error stack traces down to the specific failing lines, and structurally compress metadata. Implementing an inline text/token pruner ensures that observation bloat is neutralized right at the source.
Mem0 (mem0ai/mem0)
A self-improving memory layer designed specifically for AI agents and personalized LLM applications.
Why it matters for context engineering: Instead of storing raw conversational transcripts, Mem0 extracts and tracks persistent user preferences, system states, and factual beliefs across long-term sessions. It acts as an autonomous semantic memory graph. When an agent interacts with a user, Mem0 injects only a highly refined list of relevant current facts into the prompt, eliminating the need to pass thousands of tokens of old chat logs.
CrewAI (crewAIInc/crewAI)
A production-ready framework for orchestrating role-based, autonomous multi-agent systems.
Why it matters for context engineering: CrewAI natively handles token efficiency through strict task delegation and structured short-term/long-term memory features. By assigning distinct tasks to individual agents (e.g., Researcher, Writer), it compartmentalizes the context. Information is passed between agents only as refined, high-signal task outputs, preventing the “Observation Bloat” that occurs when a single omnipotent agent attempts to execute and track every tool step simultaneously.
LlamaIndex (run-llama/llama_index)
A data framework that connects custom data sources to LLMs, famously known for pioneering advanced RAG techniques.
Why it matters for context engineering: LlamaIndex provides robust memory abstractions such as
ChatMemoryBufferand advanced node post-processors. It allows engineers to automatically set maximum token limits on historical context retrieval, re-rank history based on semantic relevance to the current question, and apply advanced chunking strategies. This ensures that only the highest-signal context fragments are compiled into the LLM payload.
Langfuse (langfuse/langfuse)
An open-source LLM engineering platform dedicated to tracing, metrics, and prompt management.
Why it matters for context engineering: You cannot optimize what you do not measure. Langfuse allows developers to track exact token consumption, latency breakdown (including prefill vs. generation times), and full execution traces of multi-agent loops. It helps teams programmatically identify exactly which agent steps, system prompts, or tool observations are causing context bloat, making it easy to see where compression or RAG offloading needs to be applied.
Agno (agno-ai/agno)
A lightweight, developer-focused library for building multi-agent systems with native support for structured states and session storage.
Why it matters for context engineering: Agno treats agent memory as a first-class citizen. It provides robust built-in utilities to abstract chat history away from the LLM context window using customizable database backends (like PostgreSQL). It ensures that instead of passing a massive raw linear history, the agent framework handles automatic window slicing and dynamic context injection natively, keeping agent logic clean and token costs low.
DSPy (stanfordnlp/dspy)
A programmatic framework from Stanford NLP designed for compiling declarative language model prompts and architectures.
Why it matters for context engineering: Rather than relying on fragile, essay-like system prompts that consume thousands of static tokens, DSPy abstracts prompts into code modules and signatures. When optimized, DSPy automatically “compiles” the leanest, most effective prompt instructions and few-shot examples for your specific task. This eliminates conversational verbosity and manual prompt bloat, replacing it with programmatically minimal and highly deterministic token layouts.
LLMLingua (microsoft/LLMLingua)
A prompt compression engine designed to optimize long tokens using small, efficient language models (such as GPT-2 or Llama-based SLMs).
Why it matters for context engineering: LLMLingua analyzes prompts to identify and remove syntactically redundant or low-signal tokens before they reach your primary, expensive LLM. It can compress prompts by up to 20x–40x while maintaining up to 95% of the original reasoning capabilities, providing a deterministic layer against system, tool, and conversational bloat.
LangGraph (langchain-ai/langgraph)
A library developed by the LangChain team designed for building stateful, multi-actor applications with LLMs.
Why it matters for context engineering: LangGraph models agentic workflows as cyclic graphs where state is explicitly defined, centralized, and controlled. Instead of letting an agent accumulate a massive linear message history, LangGraph allows you to define strict State Reducers. You can orchestrate the system to automatically overwrite raw tool outputs, maintain a specialized short-term “scratchpad,” or trigger memory trimming hooks every time a state transition occurs.
🧑💻Let’s Coding
In the following example I implemented a simple agents scenario, using Ollama, LangGraph and Docker:
git clone https://github.com/venergiac/agenticai-context-engineering.git
docker compose upThen test
python app.py
--version llmlingua
--prompt "What are the three pillars of Physical AI mentioned in the text, and why is the Sim-to-Real approach necessary?"
--context "For decades, artificial intelligence has lived confined within screens, cloud servers, and digital software.
Language models process words and image generators manipulate pixels at extraordinary speeds, but they lack direct
interaction with the tangible world. Today, we are witnessing the most crucial technological transition of the century:
the birth of Physical AI. This discipline represents the definitive convergence of advanced computational intelligence
and the material world, enabling artificial systems to perceive, understand, move, and act autonomously within
three-dimensional physical space.
Unlike purely digital AI, Physical AI must contend with the immutable laws of physics: gravity, friction, inertia,
fluid dynamics, and the sheer unpredictability of unstructured environments. It is not simply a matter of installing
smart software into an old industrial robot. Physical AI requires a holistic design where hardware (biomimetic sensors,
high-precision actuators, compliant materials) and software (multimodal neural networks, reinforcement learning,
physics-aware simulations) evolve and operate together as a single organism.
The foundational pillars of Physical AI include:
1. Advanced Multimodal Perception: Systems fuse data from LiDAR, tactile sensors simulating human skin, pressure sensors, and inertial units.
2. Simulation-to-Real Evolution (Sim-to-Real): Training a robot in the real world is expensive and dangerous. Engineers leverage hyper-realistic digital simulations to let the AI attempt tasks millions of times in seconds, then transfer this intelligence into the physical robot.
3. Physical Commonsense Reasoning: A physical AI must grasp real-world cause and effect (e.g., understanding that a glass vase will shatter if dropped).
The application fields are vast: humanoid robotics, domestic assistants, smart prosthetics, micro-robotic surgery, Level 5 autonomous driving, and construction automation.
However, massive challenges remain: safety engineering, ethical alignment, and energy efficiency bottlenecks tied to local Edge Computing.
Despite these hurdles, Physical AI marks the end of AI as a mere 'text oracle' and ushers in the era of machines capable of tangibly reshaping reality.
"The magic stuff is done by
from llmlingua.prompt_compressor import PromptCompressor
compressor = PromptCompressor(
model_name='gpt2',
device_map='cpu',
use_llmlingua2=True
)
compressed = compressor.compress_prompt(
[prompt],
instruction="Compress this prompt for faster generation.",
question="",
rate=rate,
)["compressed_prompt"]Conclusion
When deploying AI agents in production,
fewer tokens equal a smarter agent.
Actively managing the memory window is not just a cost-saving exercise—it is a core engineering requirement to ensure long-term reasoning reliability. Shifting your focus from simple prompting to rigorous context engineering is the definitive step toward building scalable, fast, and deterministic agentic systems.